
Method
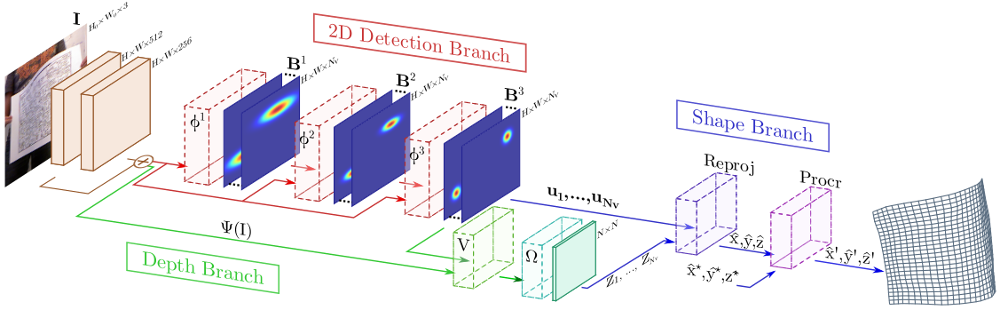
We have devised model with three branches, each responsible of reasoning about a different geometric aspect of the problem. The first two branches are arranged in parallel and perform probabilistic 2D detection of the mesh in the image plane and depth estimation (red and green regions in the figure, respectively). These two branches are then merged (blue region in the figure) in order to lift the 2D detections to 3D space, such that the estimated surface correctly re-projects onto the input image and it is properly aligned with the ground truth shape. In the results section we will show that reasoning in such a structured way provides much better results than trying to directly regress the shape from the input image, despite using considerably deeper networks.
Dataset

We have synthesized produced a photo-realistic dataset of pairs input 2D-image/3D-shape accounting for different levels of deformations, type of texture, material properties, viewpoints, lighting conditions and occlusion. If you find this dataset useful for your work cite this paper.
